


The lakehouse revolution isn't just another tech trend—it's a game-changer that's redefining how industry leaders leverage their most valuable asset: data. Forward-thinking enterprises worldwide are taking notice, and for good reason.
Are you wondering if this approach could be your competitive edge? You should be. The lakehouse architecture delivers unprecedented value by combining the best of data warehouses and data lakes into a unified, high-performance platform that's built for today's complex data challenges.
To truly appreciate where we're headed, we need to understand where we've been. Throughout the evolution of data platforms, technologies have come and gone, but the core challenge has remained constant: how to unlock maximum business value from your data with minimum complexity and cost.
This is exactly why industry leaders are rapidly adopting lakehouse architecture. It's not just an improvement—it's a fundamental shift that could redefine what's possible for your business, positioning you to make strategic decisions that transform your data capabilities and create sustainable competitive advantage.
The beginning of big data infrastructure: Hadoop and its JVM family
About 10-15 years ago, the first wave of big data platforms emerged around Hadoop, with Lambda architecture (combining batch and real-time processing) becoming the industry standard. These systems were extraordinarily complex and resource-intensive. Organizations invested heavily in specialized talent, yet the resulting systems were often fragmented collections of offline components with limited commercial viability.
During this era, technical teams would impress executives with elaborate Hadoop + Hive + Spark architecture diagrams, promising transformative data capabilities while justifying the expansion of their teams. Companies would assemble massive 50+person big data teams to build these ambitious platforms.
However, the reality fell far short of expectations:
- Data integrity issues were commonplace, with teams downplaying concerns by claiming that "a few missing records in massive datasets won't impact business operations"
- Data corrections were painfully inefficient—incorrect data required entire partitions to be deleted and reprocessed
- Storage costs ballooned as data frequently needed duplication across systems
- Despite their supposed power, these platforms would collapse when executives attempted basic queries without specifying partition keys
- Systems that initially performed well with 1 billion monthly records would deteriorate with 2 billion daily records, and by the time data volumes reached trillions of records, the original architects had typically moved on, leaving behind platforms that required complete reconstruction
- The excessive complexity (often 30+ components) meant that upgrading any single element risked breaking the entire system
- The fragmented architecture created security vulnerabilities with each additional component
- Query planning alone could take minutes, with execution plans rendered impractical by metadata overload from excessive partitioning
- Even seemingly straightforward tasks like deduplication would overwhelm teams
The list of frustrations was virtually endless....

This generation of big data platforms became a source of constant anxiety for executives. Real-world implementation revealed that these architectures not only failed to deliver on their promises but often led companies into strategic dead ends. Data engineers found themselves trapped in endless cycles of data loading and preparation using Spark and Hadoop, while downstream business users remained unable to extract meaningful value from their data investments.
Spark-based lakehouse: simpler but not simple enough
In this evolution, the industry made significant progress toward simplification. Data lakes adopted more structured approaches with Apache Iceberg format providing a robust table format for massive datasets. By leveraging Apache Spark and Apache Flink, organizations reduced their architecture from 30+ components to roughly 10 core technologies, allowing teams to shrink from 50+ specialists to about 10.
This second-generation lakehouse focused on specific technical challenges:
- Managing Iceberg's historical versions, compaction operations, and Z-order processing
- Implementing Shuffle services for distributed processing
- Maintaining security across integrated components
- Building intelligent SQL Gateways to route queries appropriately
These improvements delivered meaningful benefits:
- ACID transaction support ensuring data reliability
- Consistent metadata management across the ecosystem
- Unified storage eliminating redundant data duplication
However, significant challenges remained:
- Organizations still needed 10+ specialized engineers just for maintenance
- The architecture required senior Spark experts, particularly challenging when handling billions to trillions of records
- Practical limitations emerged: infra team generally set a serious of limitations like single tables couldn't exceed 10 billion records, and databases needed to stay under 10,000 tables to avoid system degradation
- Exceeding these limits often resulted in system instability, missed SLAs, and engineering burnout
These persistent challenges explain why managed solutions like Snowflake, Databend and Databricks gained such tremendous market traction. Organizations increasingly recognized that the technical complexity and operational overhead of maintaining these systems in-house simply wasn't worth the effort compared to fully-managed alternatives offering similar capabilities with significantly reduced operational burden.
Cloud-Native, Self-driven lakehouse: The Evolution We've Been Waiting For
After witnessing the painful journey through previous data architecture generations, the industry has crystallized what truly matters in a modern lakehouse solution:
Simplicity is the ultimate sophistication. A truly effective lakehouse must eliminate complexity at every level - from deployment and scaling to daily operations and user experience. It should free your technical teams from mundane maintenance tasks and empower them to deliver actual business value.
This fundamental insight drove us to create Databend in 2021 - a solution that finally delivers on the lakehouse promise without the traditional overhead and complexity.
The Databend Difference: Simplicity with Enterprise Power
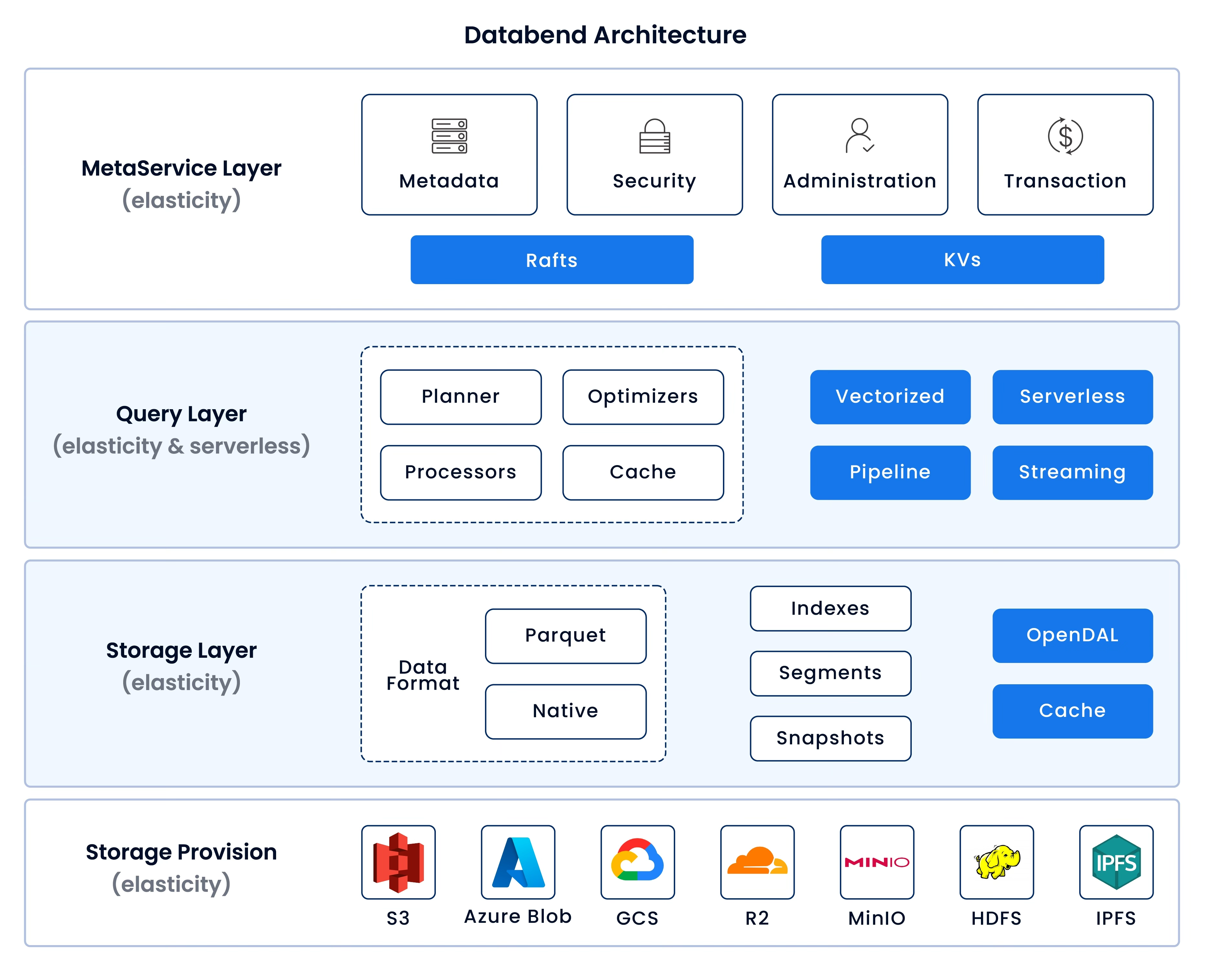
1. True Cloud-Native Architecture
Databend was built from first principles with a diskless, S3-native design. Unlike retrofitted solutions, our architecture requires minimal infrastructure - just a few compute nodes atop your existing S3 storage. No complex caching layers, no specialized hardware requirements. Scaling becomes trivially simple: add compute resources when needed, and your performance and concurrency scale linearly with your business demands.
2. Zero-Maintenance Operations
We've eliminated the operational burden that plagued previous generations. Databend intelligently handles all the tedious background tasks - compaction, reclustering, optimization - automatically maintaining peak performance without human intervention. Whether you choose our self-hosted enterprise version or cloud offering, your team is finally free from the endless cycle of maintenance firefighting.
3. Seamless Migration Path
We understand that technology transitions must be practical. That's why Databend supports the tools and workflows your team already knows - from familiar SQL syntax to popular language drivers, UDFs, and integrations with tools like DBT, Airbyte, DBeaver, and Tableau. Your existing skills transfer directly to our platform, eliminating painful retraining cycles.
Real-World Transformation: Gaming Industry Case Study
A leading gaming company with 100M+ monthly active users was struggling with their data infrastructure. Their CTO put it bluntly: "Every minute of analytics delay costs us approximately $10,000 in revenue opportunity. With our current setup, we're leaving millions on the table."
Their requirements were clear:
- Sub-second data ingestion for player behavior analysis
- Support for 5,000+ concurrent streaming computations during peak hours
- Processing of 100+ billion monthly events with consistent performance
After implementing Databend, the results were immediate:
From Data Wrangling to Revenue Generation
"We cut our data preparation cycle from 48 hours to 30 minutes," their Director of Analytics reported. "Game designers now optimize monetization strategies based on same-day insights rather than week-old data." By processing diverse data formats directly with standard SQL, they eliminated their Spark engineering team, saving $1.2M annually.
From Complex Streaming to Simple Solutions
Their Lead Architect explained: "We replaced our entire Flink cluster with Databend's UDF capabilities. A single engineer now implements features that previously required specialized teams." This enabled critical player-retention features like post-match analysis to deploy in days instead of months, with automatic scaling handling 10x traffic spikes during tournaments.
From Infrastructure Management to Business Innovation
"We've shifted 60% of our engineering resources from maintenance to innovation," noted their CTO. "While competitors struggle with their data platforms, we're shipping new features weekly." The business impact was clear: 22% increase in player retention and 15% growth in in-game purchases directly tied to faster analytics capabilities.
The Future Belongs to Those Who Simplify

Let's be honest - the data architecture journey has been unnecessarily painful. We've collectively spent billions on complex systems that required armies of specialists just to keep running. The promise of insights-driven business has too often been buried under infrastructure complexity.
Databend was born from this frustration. As practitioners who lived through these challenges, we built what we wished had existed all along - a lakehouse that simply works.
The results speak for themselves:
- Companies reducing their data engineering teams by 60-70%
- Analytics cycles compressed from days to minutes
- Infrastructure costs cut by 40-60% while handling larger workloads
- Business teams empowered to answer their own questions without technical bottlenecks
This isn't just incremental improvement - it's a fundamental shift in how organizations can approach their data strategy. The company case study isn't an outlier - it's what becomes possible when you remove the artificial complexity that's been holding your data initiatives back.
The most powerful technologies are those that fade into the background, doing their job so reliably that you barely notice them. That's the future Databend delivers - where your team's energy goes into extracting business value from data, not babysitting infrastructure.
The choice is clear: continue investing in increasingly complex architectures that demand specialized skills, or embrace a solution that finally delivers on the lakehouse promise without the traditional overhead. Your competitors are already making this decision - which side of the divide will you be on?
Subscribe to our newsletter
Stay informed on feature releases, product roadmap, support, and cloud offerings!

